Задача: Создать парсер книг для мониторинга цен конкурентов для интернет-магазина CLOUDS SHOP
CLOUDS SHOP - интернет-магазин, занимающийся продажей эзотерических товаров.
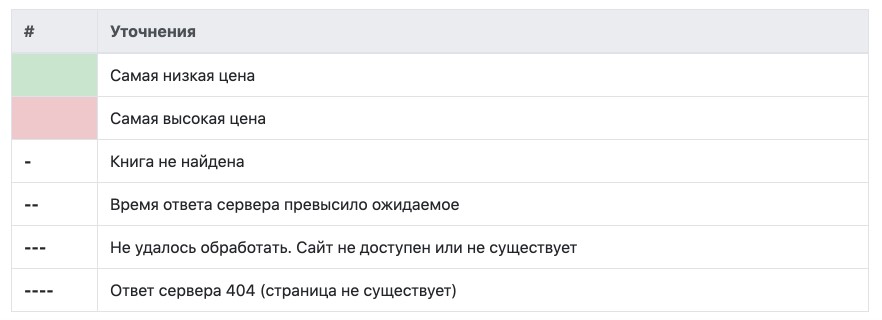
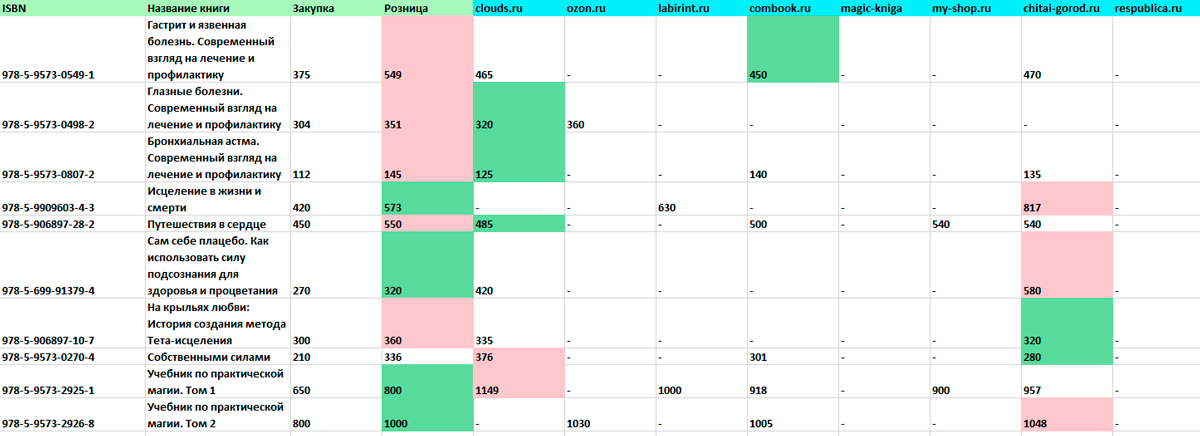
В рамках поставленной задачи был разработан парсер, который ищет на указанных в конфигурационном файле сайтах книги по уникальному номеру ISBN. На выходе получаем файл в формате XLS (XLSX), в котором указаны цены на запрашиваемые книги с подсветкой самой низкой и самой высокой цен сайтов-конкурентов.
Пример файла для загрузки можно посмотреть на страничке Парсер книг и скачать.
В парсере есть отдельный класс для валидации входных данных, который выводит на экран найденные ошибки с указанием на конкретную ячейку с ошибкой.
В нижнем углу экрана выведена информация о поиске и чтении файла, обновляемая в реальном времени.

При разработке предусмотрели такой вариант, при котором парсинг можно приостановить в любой момент, и загружаемый файл можно парсить с указанной строки, так как количество строк в файле может быть очень большим, и пользователь не успевает прогнать его полностью или же просто хочет прервать выполнение скрипта. Или прервалось соединение с сервером. В таком случае можно продолжить выполнение скрипта с нужной строки.
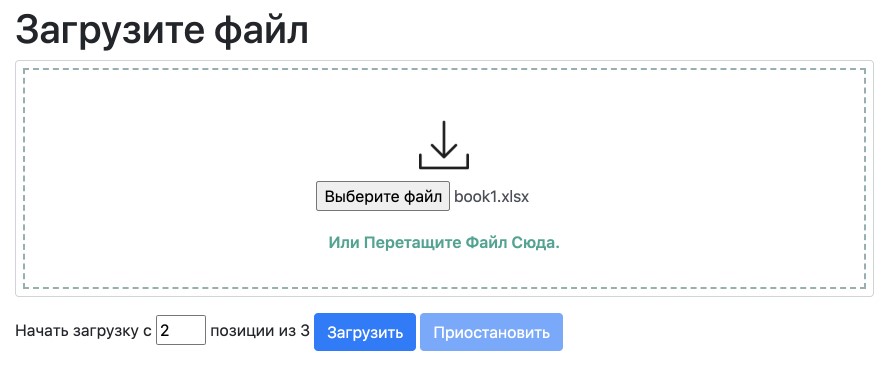
На парсинг книг на каждом из сайтов дается три попытки на случай того, что сервер не успевает прогрузить страничку в течение указанного в запросе таймаута или возникают иные ошибки на стороне запрашиваемых сайтов.
После успешного поиска и парсинга книг формируем файл с результатами выполнения запросов, и итоговый файл доступен для скачивания.
В документации к парсеру указаны все символы и цвета заливки ячеек, которые могут встретиться в выходном файле.